
Last week, I launched notesGPT, a free and open source voice note app that has 35,000 visitors, 7,000 users, and over 1,000 GitHub stars so far in the last week. It allows you to record a voice note, transcribes it uses Whisper, and uses Mixtral via Together to extract action items and display them in an action items view. It’s also fully open source and comes equipped with authentication, storage, vector search, action items, and is fully responsive on mobile for ease of use.
I’m going to to walk you through exactly how I built it.
Architecture and tech stack
This is a quick diagram for the architecture. We’ll be discussing each piece in more depth and also showing code examples as we go.
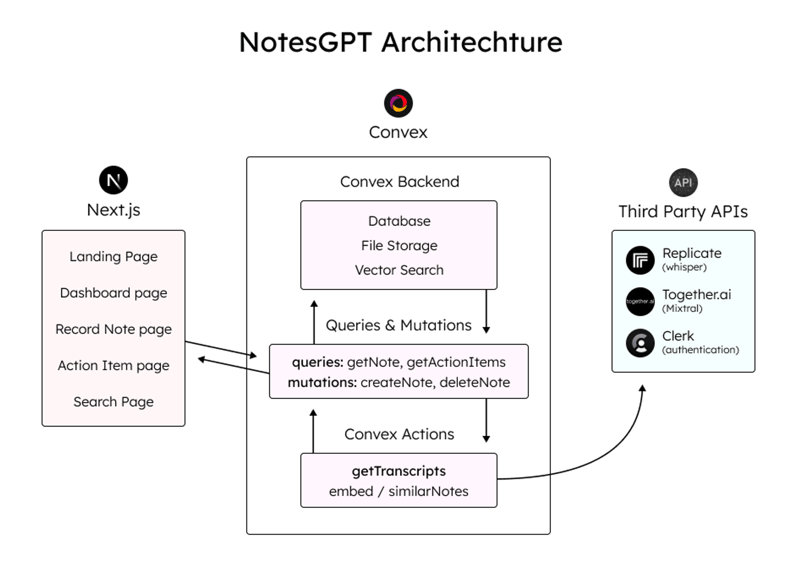
Here’s the overall tech stack I used:
- Convex for the database and cloud functions
- Next.js App Router for the framework
- Replicate for Whisper transcriptions
- Mixtral with JSON mode for the LLM
- Together.ai for inference and embeddings
- Convex File Storage for storing voice notes
- Convex Vector search for vector search
- Clerk for user authentication
- Tailwind CSS for styling
Landing Page
The first piece of the app is the landing page you see when you navigate to notesGPT.
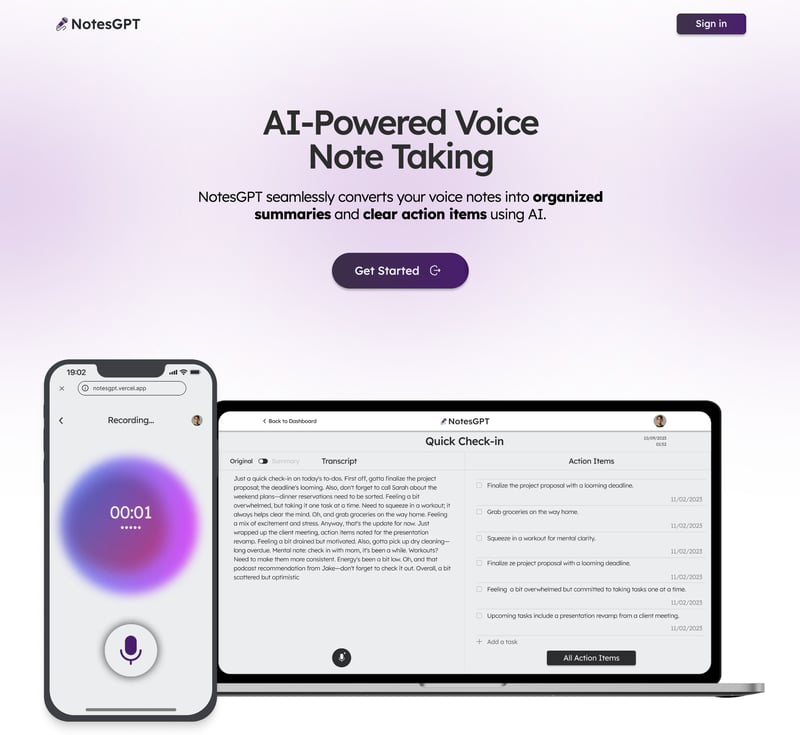
The first things users see is this landing page which along with the rest of the app, was built with Next.js and with Tailwind CSS for styling. I enjoy using Next.js since it makes it it easy to spin up web apps and just write React code. Tailwind CSS is great too since it allows you to iterate quickly on your web pages while staying in the same file as your JSX.
Authentication with Clerk and Convex
When the user clicks either of the buttons on the homepage, they get directed to the sign in screen. This is powered by Clerk, an easy authentication solution that integrates well with Convex, which is what we’ll be using for our entire backend including cloud functions, database, storage, and vector search.
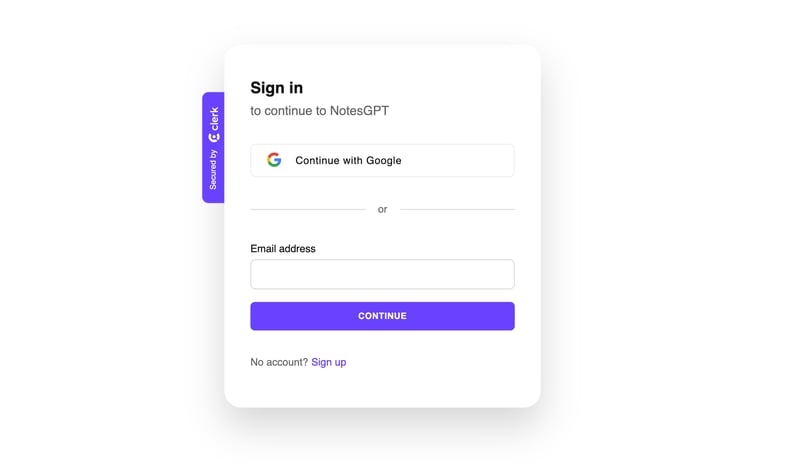
Clerk and Convex are both easy to setup. You can simply create an account on both services, install their npm libraries, run npx convex dev to setup your convex folder, and create a ConvexProvider.ts file as seen below to wrap your app with.
'use client';
import { ReactNode } from 'react';
import { ConvexReactClient } from 'convex/react';
import { ConvexProviderWithClerk } from 'convex/react-clerk';
import { ClerkProvider, useAuth } from '@clerk/nextjs';
const convex = new ConvexReactClient(process.env.NEXT_PUBLIC_CONVEX_URL!);
export default function ConvexClientProvider({
children,
}: {
children: ReactNode;
}) {
return (
<ClerkProvider
publishableKey={process.env.NEXT_PUBLIC_CLERK_PUBLISHABLE_KEY!}
>
<ConvexProviderWithClerk client={convex} useAuth={useAuth}>
{children}
</ConvexProviderWithClerk>
</ClerkProvider>
);
}
Check out the Convex Quickstart and the Convex Clerk auth section for more details.
Setting up our schema
You can use Convex with or without a schema. In my case, I knew the structure of my data and wanted to define it so i did so below. This also gives you a really nice type-safe API to work with when interacting with your database. We’re defining two tables – a notes table to store all voice note information and actionItems table for extracted action items. We’ll also define indexes to be able to quickly query the data by userId and noteId.
import { defineSchema, defineTable } from 'convex/server';
import { v } from 'convex/values';
export default defineSchema({
notes: defineTable({
userId: v.string(),
audioFileId: v.string(),
audioFileUrl: v.string(),
title: v.optional(v.string()),
transcription: v.optional(v.string()),
summary: v.optional(v.string()),
embedding: v.optional(v.array(v.float64())),
generatingTranscript: v.boolean(),
generatingTitle: v.boolean(),
generatingActionItems: v.boolean(),
})
.index('by_userId', ['userId'])
.vectorIndex('by_embedding', {
vectorField: 'embedding',
dimensions: 768,
filterFields: ['userId'],
}),
actionItems: defineTable({
noteId: v.id('notes'),
userId: v.string(),
task: v.string(),
})
.index('by_noteId', ['noteId'])
.index('by_userId', ['userId']),
});
Dashboard
Now that we have our backend and authentication setup along with our schema, we can take a look at fetching data. After signing into the app, users can view their dashboard which lists all of the voice notes they’ve recorded.
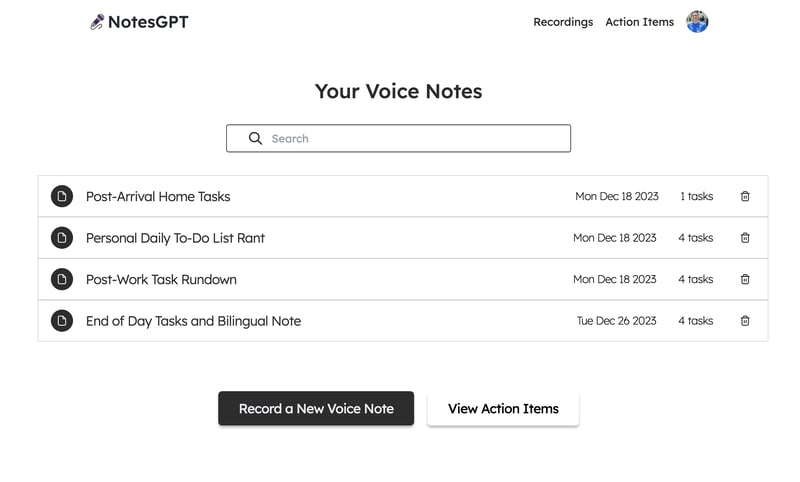
To do this, we first define a query in the convex folder that uses auth to take in a userId, verify it’s valid, and returns all the notes that match a user’s userId.
export const getNotes = queryWithUser({
args: {},
handler: async (ctx, args) => {
const userId = ctx.userId;
if (userId === undefined) {
return null;
}
const notes = await ctx.db
.query('notes')
.withIndex('by_userId', (q) => q.eq('userId', userId))
.collect();
const results = Promise.all(
notes.map(async (note) => {
const count = (
await ctx.db
.query('actionItems')
.withIndex('by_noteId', (q) => q.eq('noteId', note._id))
.collect()
).length;
return {
count,
...note,
};
}),
);
return results;
},
});
After this, we can call this getNotes query with a user’s authentication token via a function that convex provides to display all the user’s notes in the dashboard. We’re using server side rendering to fetch this data on the server then passing it into the <DashboardHomePage /> client component. This also ensures that the data stays up to date on the client as well.
import { api } from '@/convex/_generated/api';
import { preloadQuery } from 'convex/nextjs';
import DashboardHomePage from './dashboard';
import { getAuthToken } from '../auth';
const ServerDashboardHomePage = async () => {
const token = await getAuthToken();
const preloadedNotes = await preloadQuery(api.notes.getNotes, {}, { token });
return <DashboardHomePage preloadedNotes={preloadedNotes} />;
};
export default ServerDashboardHomePage;
Recording a voice note
Initially, users won’t have any voice notes on their dashboard so they can click the “record a new voice note” button to record one. They’ll see the following screen that will allow them to record.
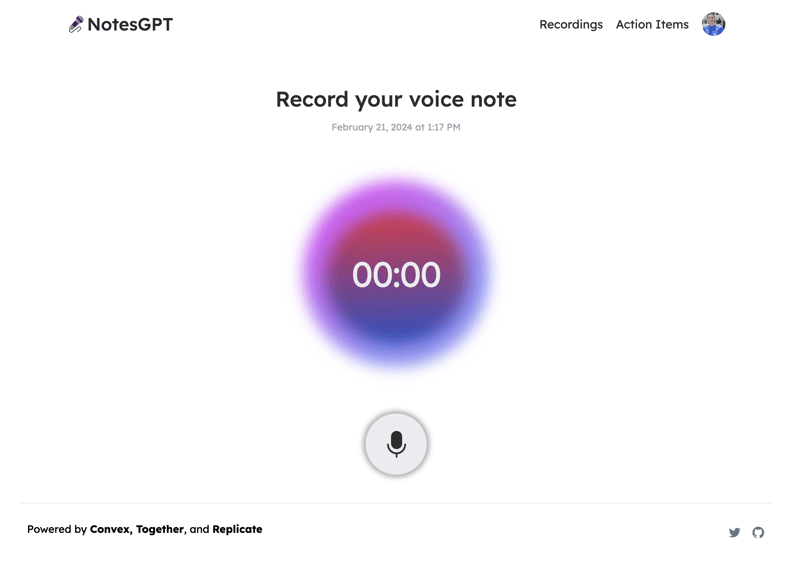
This will record a voice note using native browser APIs, save the file in Convex file storage, then send it to Whisper through Replicate to be transcribed. The first thing we do is define a createNote mutation in our convex folder that will take in this recording, save some information in the Convex database, then call the whisper action.
export const createNote = mutationWithUser({
args: {
storageId: v.id('_storage'),
},
handler: async (ctx, { storageId }) => {
const userId = ctx.userId;
let fileUrl = (await ctx.storage.getUrl(storageId)) as string;
const noteId = await ctx.db.insert('notes', {
userId,
audioFileId: storageId,
audioFileUrl: fileUrl,
generatingTranscript: true,
generatingTitle: true,
generatingActionItems: true,
});
await ctx.scheduler.runAfter(0, internal.whisper.chat, {
fileUrl,
id: noteId,
});
return noteId;
},
});
The whisper action is seen below. It uses Replicate as the hosting provider for Whisper.
export const chat = internalAction({
args: {
fileUrl: v.string(),
id: v.id('notes'),
},
handler: async (ctx, args) => {
const replicateOutput = (await replicate.run(
'openai/whisper:4d50797290df275329f202e48c76360b3f22b08d28c196cbc54600319435f8d2',
{
input: {
audio: args.fileUrl,
model: 'large-v3',
translate: false,
temperature: 0,
transcription: 'plain text',
suppress_tokens: '-1',
logprob_threshold: -1,
no_speech_threshold: 0.6,
condition_on_previous_text: true,
compression_ratio_threshold: 2.4,
temperature_increment_on_fallback: 0.2,
},
},
)) as whisperOutput;
const transcript = replicateOutput.transcription || 'error';
await ctx.runMutation(internal.whisper.saveTranscript, {
id: args.id,
transcript,
});
},
});
Also, all these files can be seen in the Convex dashboard under “Files”.
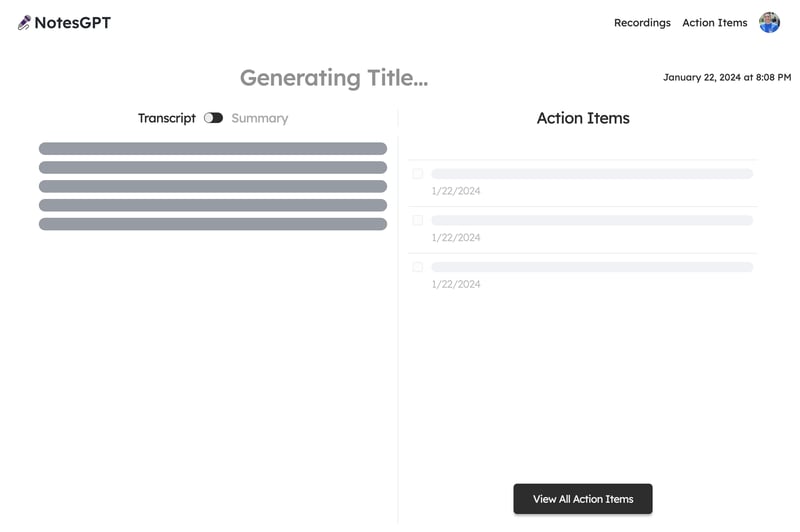
Generating action items
After the user finishes recording their voice note and it gets transcribed via whisper, the output is then passed into Together AI. We show this loading screen in the meantime.
We first define a schema that we want our output to be in. We then pass this schema into our Mixtral model hosted on Together.ai with a prompt to identify a summary of the voice note, a transcript, and generate action items based on the transcript. We then save all this information to the Convex database. To do this, we create a Convex action in the convex folder.
// convex/together.ts
const NoteSchema = z.object({
title: z
.string()
.describe('Short descriptive title of what the voice message is about'),
summary: z
.string()
.describe(
'A short summary in the first person point of view of the person recording the voice message',
)
.max(500),
actionItems: z
.array(z.string())
.describe(
'A list of action items from the voice note, short and to the point. Make sure all action item lists are fully resolved if they are nested',
),
});
export const chat = internalAction({
args: {
id: v.id('notes'),
transcript: v.string(),
},
handler: async (ctx, args) => {
const { transcript } = args;
const extract = await client.chat.completions.create({
messages: [
{
role: 'system',
content:
'The following is a transcript of a voice message. Extract a title, summary, and action items from it and answer in JSON in this format: {title: string, summary: string, actionItems: [string, string, ...]}',
},
{ role: 'user', content: transcript },
],
model: 'mistralai/Mixtral-8x7B-Instruct-v0.1',
response_model: { schema: NoteSchema, name: 'SummarizeNotes' },
max_tokens: 1000,
temperature: 0.6,
max_retries: 3,
});
const { title, summary, actionItems } = extract;
await ctx.runMutation(internal.together.saveSummary, {
id: args.id,
summary,
actionItems,
title,
});
});
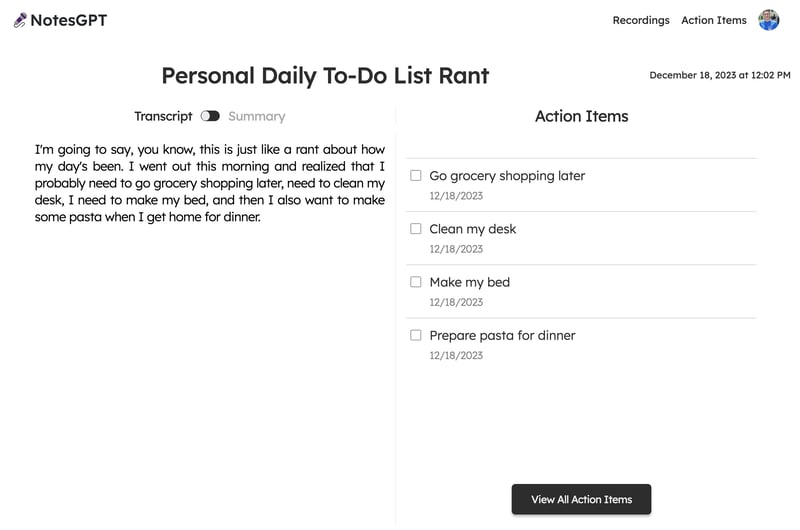
When Together.ai responds, we get this final screen which lets users toggle between their transcript and a summary on the left, and see and check off the action items on the right.
Vector Search
The final piece of the app is vector search. We’re using Together.ai embeddings to embed the transcripts and make it possible for folks to search in the dashboard based on the semantic meaning of the transcripts.
We do this by creating a similarNotes action in the convex folder that takes in a user’s search query, generates an embedding for it, and finds the most similar notes to display on the page.
export const similarNotes = actionWithUser({
args: {
searchQuery: v.string(),
},
handler: async (ctx, args): Promise<SearchResult[]> => {
// 1. Create the embedding
const getEmbedding = await togetherai.embeddings.create({
input: [args.searchQuery.replace('/n', ' ')],
model: 'togethercomputer/m2-bert-80M-32k-retrieval',
});
const embedding = getEmbedding.data[0].embedding;
// 2. Then search for similar notes
const results = await ctx.vectorSearch('notes', 'by_embedding', {
vector: embedding,
limit: 16,
filter: (q) => q.eq('userId', ctx.userId), // Only search my notes.
});
return results.map((r) => ({
id: r._id,
score: r._score,
}));
},
});
Conclusion
Just like that, we’ve built a production-ready full-stack AI app ready with authentication, a database, storage, and APIs. Feel free to check out notesGPT to generate action items from your notes or the GitHub repo for reference. And if you had any questions, shoot me a DM and I’d be more than happy to answer it!


















